The Four Layers Every Enterprise AI Architecture Needs (And Most Are Missing Two)
Most enterprises buy AI for layers 1 and 3, skip 2 and 4, and wonder why nothing decides anything. Here's the architecture that actually works.
The stack looks impressive. Nothing decides anything.
A CIO walked me through her AI roadmap last quarter. It was, on paper, a thing of beauty.
Two LLM vendors under enterprise contract. A vector database with five named retrieval pipelines. A copilot rolled out to 4,000 seats. Three dashboards stitched on top of a freshly minted lakehouse. A governance committee. A center of excellence. Eight pilots in flight, two more in procurement.
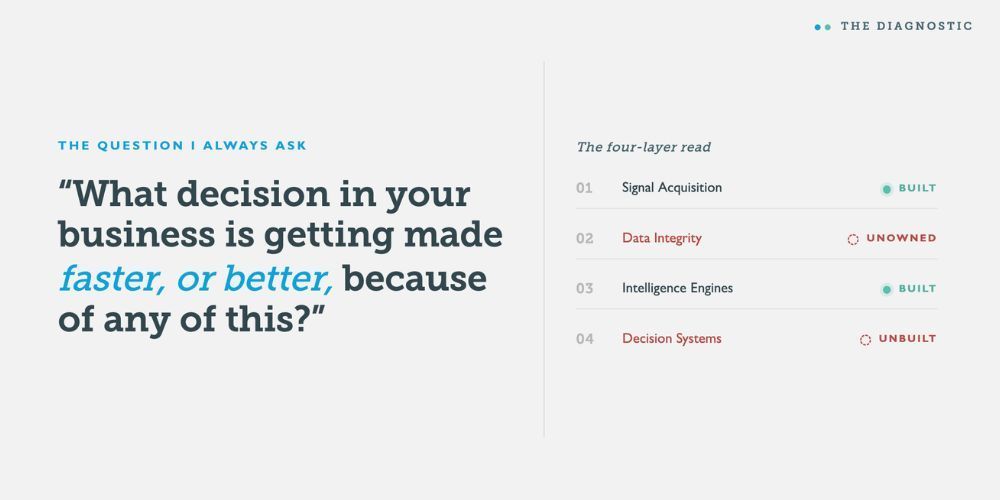
Then I asked the question I always ask.
"What decision in your business is getting made faster, or better, because of any of this?"
Long pause. She named one. It was a content tagging workflow.
I have had some version of that conversation a dozen times in the last eighteen months. The companies are different. The vendors rotate. The pause is the same.
Here is what I have come to believe, and I think it is the uncomfortable truth most enterprise AI programs are working around: the technology is not the problem. The architecture is.
Most enterprises have bought layers 1 and 3. They have signal sources, and they have models. What they do not have, and what they keep being surprised they do not have, are the two layers in between and after that turn signals into decisions.
This is what I want to walk through. Not as a product pitch. As a diagnostic.

The four-layer pattern
I did not set out to design a framework. It revealed itself by solving the same problem repeatedly across consulting engagements, internal builds, and the AI lab work I run now. Every system that actually produced operational decisions had the same four layers. Every system that stalled was missing one or two of them, usually the same two.
I call the framework InsightStack. The layers are:
- Signal Acquisition — where raw inputs come from
- Data Integrity — where signals get cleaned, deduplicated, normalized, and made trustworthy
- Intelligence Engines — where domain-specific models extract structured insight
- Decision Systems — where insight becomes an action, a recommendation, or a workflow trigger
The flow is linear in description, modular in practice. Each layer has its own owner, its own success metric, its own failure mode. And critically, each layer is replaceable without rebuilding the others. That is what makes it an architecture instead of a stack.
Let me take them in order.
Layer 1: Signal Acquisition
This is the layer everyone buys first. Customer data platforms. Marketing analytics. Sales conversation tools. Community listening platforms. Search trend feeds. Marketplace scrapers. Internal telemetry. Survey instruments.
The job of this layer is simple to state and hard to do: capture the inputs that actually carry decision-relevant information.
Most enterprises overbuild here. They have eleven sources of customer signal and three sources of competitive signal and four sources of operational signal, and almost none of it talks to each other. The signal acquisition layer is rarely the bottleneck. It is usually the bloat.
If your team can list more than fifteen "data sources" without flinching, you have a signal acquisition layer. You probably have too much of it.
Layer 2: Data Integrity
Here is where most programs quietly fall apart.
Signals arrive messy. Duplicate records. Inconsistent naming. Entity confusion (is "Acme Corp" the same as "Acme Corporation" the same as "ACME"?). Schema drift. Stale fields. Records that say one thing in Salesforce and another in HubSpot and a third in the warehouse. Free-text fields where someone typed "TBD" three years ago and nobody flagged it.
Layer 2's job is to make those signals trustworthy enough that a model can reason against them without inheriting their problems.
This is unglamorous work. Semantic deduplication. Entity resolution. Normalization. Reference data governance. Schema reconciliation. It does not demo well. It does not generate a buzzy LinkedIn post. It does not get an enterprise architect promoted.
It is also the layer that determines whether everything downstream works.
Palantir built a multi-billion-dollar business essentially on this layer. They call it Ontology. The naming is theirs. The principle is universal: if your AI is reasoning against unclean, unresolved, unreliable data, your AI is producing unclean, unresolved, unreliable conclusions. Faster, at scale, with more confidence than the data deserves.
This is the first of the two layers most enterprises skip. Not because they do not know it matters. Because the org chart does not have a clear owner. Data engineering owns the pipes. Analytics owns the dashboards. Marketing owns the campaigns. The actual condition of the data, the thing that makes models trustworthy, sits in nobody's quarterly objectives.
So it does not get done. And then six months into a flagship AI initiative, somebody whispers what everyone already suspected: the data is the problem.
Layer 3: Intelligence Engines
This is what most people mean when they say "AI." It is the model layer. The reasoning layer. The place where structured signals get interpreted into structured insight.
A few patterns I have seen work and not work here.
Single-model architectures rarely scale. A general-purpose LLM with a clever prompt is a wrapper, not an engine. It will solve one problem competently and ten problems mediocrely. The companies getting real value from this layer are running multiple domain-specific engines, each tuned to a narrow class of decision: customer segmentation here, pricing intelligence there, demand forecasting somewhere else.
This is the consulting AI pattern. McKinsey's QuantumBlack does not run one model. BCG X does not run one model. They run portfolios of domain engines on top of a shared infrastructure. Each engine solves a distinct decision problem. Each one is replaceable. Each one is measurable.
If your AI strategy fits on a slide titled "Our LLM Vendor," you have a wrapper, not a portfolio.
Layer 4: Decision Systems
This is the other layer most enterprises skip, and it is the one that hurts most.
Layer 4 takes the output of the intelligence engines and turns it into something operational. A recommendation in a workflow. A flag in a queue. A confidence-scored option presented to a human at the moment of decision. A trigger that updates a campaign, opens a ticket, reroutes a lead, escalates a risk.
Without this layer, intelligence is a report. With this layer, intelligence is leverage.
Here is the painful truth. A startling share of enterprise AI investment dies in dashboards. The model runs. The output is correct. It goes into a Tableau view that three people look at on Mondays. The decision is still made by the same person, on the same timeline, with the same heuristics, with maybe a glance at the dashboard if there is time.
That is not an AI program. That is an analytics program with a more expensive backend.
Decision Systems is where you close the loop. It is where insight becomes workflow. It is where the model output meets the operating system of the business, and changes how something actually gets decided.
Most enterprises have not built this layer because building it requires something harder than buying software: it requires changing how a decision gets made. Which means it requires a process owner, not just a technology owner. And process owners are usually not in the room when the AI strategy gets drafted.
Why layers 2 and 4 get skipped
I want to be honest about something. Layers 2 and 4 do not get skipped because executives are stupid or vendors are evil. They get skipped because of structural incentives that are almost invisible from the inside.
Layer 1 has vendors. They are loud, well-funded, and they will sell you a contract this quarter. Layer 3 has vendors. They are even louder. They will sell you a model, a copilot, a fine-tuning service, a vector store, a retrieval pipeline, and a launch event with a CEO keynote.
Layer 2 does not have a vendor category that maps cleanly. Data quality, MDM, entity resolution, ontology, governance — those words live in different categories on the Gartner Magic Quadrant, owned by different teams, sold by different reps, and they do not feel like AI. So they do not get funded in the AI budget. They get funded in the data budget. Which is smaller. And older. And nobody is excited about it.
Layer 4 is even worse, because it is not a vendor problem. It is a workflow problem. To build Layer 4, you need to redesign how a specific decision is made inside the business. That is change management. That is operations. That is, frankly, hard.
So enterprises buy what is buyable. They buy Layer 1 and Layer 3. They demo well. They generate progress. They produce roadmaps and announcements and pilot numbers.
And six quarters later, the CIO is sitting in a board meeting trying to explain why a $40M AI investment has not yet produced a measurable change in any business outcome.
What missing layers cost
I want to put rough numbers on this, with the caveat that these are patterns I have observed across engagements rather than a controlled study.
When Layer 2 is missing or underbuilt:
Pilot velocity drops by half or more. Every initiative spends most of its lifecycle on data wrangling before any modeling work begins. Production deployment rates are abysmal. The often-cited figure that something like 70% of enterprise AI pilots never reach production is, in my experience, largely a Layer 2 failure dressed up as a Layer 3 problem.
When Layer 4 is missing or underbuilt:
The models work and nothing changes. ROI calculations turn into hand-waving. Adoption stalls because the people who would use the insight have not had their workflow redesigned to consume it. The program produces dashboards instead of decisions. Eventually the executive sponsor moves on, and the initiative quietly enters maintenance mode.
Both failure modes are recoverable. Neither is recoverable cheaply.
A diagnostic you can run today
If you want a fast read on your own architecture, here are the five questions I work through with executive teams. Answer honestly. The point is not to score well. The point is to see what you have.
- For our top three AI use cases, can we name the specific decision each one is meant to improve? If the answer is general ("better customer insight," "faster reporting"), you do not have a use case. You have a wish.
- Who owns the trustworthiness of the data feeding our models? Not the pipes. The condition. If no one's name comes up immediately, Layer 2 is unowned.
- What percentage of our AI investment is going to Layer 2 and Layer 4 versus Layer 1 and Layer 3? If the split is worse than 70/30 toward layers 1 and 3, you are buying capability without buying outcome.
- For our most active production AI system, what is the human workflow that consumes its output? If you cannot describe it in a sentence, Layer 4 is not built.
- If we shut off our most prominent AI vendor tomorrow, which business outcomes would visibly degrade? If the answer is "none that we can prove," you have a Layer 4 problem dressed up as a vendor problem.
These are not gotcha questions. They are the questions I ask before any architecture engagement, because the answers tell me where to look first. In nine out of ten cases, the answers point to Layer 2 and Layer 4.
Where to start
If this diagnostic landed somewhere uncomfortable, a few suggestions.
Stop buying. Audit. Most enterprises do not need another vendor in Layer 1 or Layer 3. They need to know what they already have and whether it is producing decisions.
Find an owner for Layer 2. One person, with authority, whose objective is the trustworthiness of the data behind the models. Not the data engineering manager who already has eleven other priorities. A real owner.
Pick one decision and build Layer 4 around it. Not a portfolio. One decision. Map the current workflow, redesign it with model output embedded at the right point, measure the change in decision quality and decision speed. That is your proof of concept. Not the model. The decision.
Treat the four layers as a system. Investing heavily in one layer while neglecting another is not a strategy. It is a tax on the layers that are working.
I built InsightStack as the architectural lens I use across my client work and my own product portfolio. The names are mine. The pattern is older than the framework. Palantir, the consulting firms, the better vertical AI startups — they all converge on this same four-layer shape, because the shape is what produces decisions instead of demos.
You can call it whatever you want. Just make sure all four layers are in your architecture.
Otherwise you are building an impressive stack that does not decide anything. And in 2026, that is no longer a defensible position.
Frequently Asked Questions
How is this different from a standard data and AI maturity model?
Maturity models describe where you are on a journey. This is an architectural diagnostic. It tells you which parts of your system exist, which are missing, and which are doing structural work that no one has assigned. The two are complementary. You can be at a high level of maturity on a standard model and still be missing Layer 2 or Layer 4, because most maturity models do not separate those layers cleanly from data engineering and analytics.
Does every enterprise need all four layers in-house?
No. Each layer can be built, bought, partnered, or outsourced. What is non-negotiable is that each layer has a named owner, a clear success metric, and a path for output to flow into the next layer. The failure mode is not "we did not build Layer 2 ourselves." The failure mode is "Layer 2 belongs to no one."
Where does governance fit?
Governance, compliance, and risk management cut across all four layers. They are not a fifth layer. They are an overlay. The reason I do not draw them as a separate layer is that organizations treating governance as a separate workstream tend to discover at the worst possible moment that their AI initiative was non-compliant from the signal acquisition stage onward. Governance belongs in every layer, owned jointly with the layer owner.


