Your Data Is Lying to You (And Your AI Believes Every Word)
AI doesn't fix dirty data — it scales the damage. How data quality debt compounds in production AI systems, and what you can actually do about it.
The silent failure mode no one wants to talk about in enterprise AI
There's a specific kind of meeting I've sat through more times than I can count. A leadership team, freshly energized from an AI strategy offsite, starts talking about what they're going to build. New models. New automation. New pipelines. A whole future constructed on the premise that their organization will finally stop leaving insight on the table.
Then someone asks the question nobody prepared for: What's the state of our data?
Silence. A little throat-clearing. Someone mentions a "data governance initiative" that started two years ago. Another person references the CRM migration that was "mostly complete." The VP of Marketing notes that the segmentation team has been wrestling with some "duplication issues."
This is the moment. Right here. This is where most AI initiatives actually die — not in the model selection phase, not in the vendor negotiation, not in the change management rollout. They collapse because the organization fed a very expensive, very sophisticated system a diet of garbage.
And the AI? It didn't complain. It just got to work.

The Myth That Scale Fixes Everything
Somewhere along the way, a comforting story took hold: AI is so powerful it can work around messy data. That given enough volume, signal will emerge from noise. That the model is smart enough to compensate.
That story is wrong. And it's costing companies real money.
Here's what scale actually does to bad data: it amplifies every flaw. A duplicate contact record in your CRM is an annoyance. Feed that same record into an AI model that's scoring leads, personalizing outreach, and forecasting pipeline, and you've just institutionalized the error at machine speed. The model doesn't know the contact is a duplicate. It treats both records as distinct signals, learns from both, and builds its understanding of your customer base on a foundation that was compromised before the first query ran.
This is what I mean by data quality debt. It's not a metaphor. It's a compounding liability that grows faster once AI enters the picture, because AI removes the human checkpoints that used to catch the worst of it.
Why AI Makes Bad Data Worse (Not Better)
Let me push back on something you've probably heard from a vendor or a consultant in the last eighteen months: "Our AI can handle imperfect data."
Technically true. Practically catastrophic.
Yes, modern machine learning models are robust to a certain level of noise. Yes, some architectures are specifically designed with data imperfection in mind. But "handling" imperfect data is not the same as producing reliable outputs from it. What these systems are doing is making confident predictions based on flawed inputs — and they do it without flagging uncertainty, without surfacing contradictions, without telling you that 23% of the records in your training set had conflicting firmographic attributes.
They just... answer.
That's the insidious part. AI doesn't fail loudly when data is dirty. It fails quietly. It produces results that look authoritative, that have decimal-point precision, that get put into dashboards and presented in QBRs as ground truth. The error is invisible until it's expensive.
I've seen this pattern play out in enterprise contexts with meaningful consequences. A segmentation model that confidently surfaces the wrong cohort for a drug launch campaign — because the HCP contact data feeding it hadn't been reconciled across three source systems in over a year. A churn prediction model that flags the wrong accounts — because the product usage data it ingested had a field mapping error that no one caught during the ETL build. A customer lifetime value model trained on revenue data that double-counted transactions during a platform migration.
In each case, the AI worked exactly as designed. The data didn't.
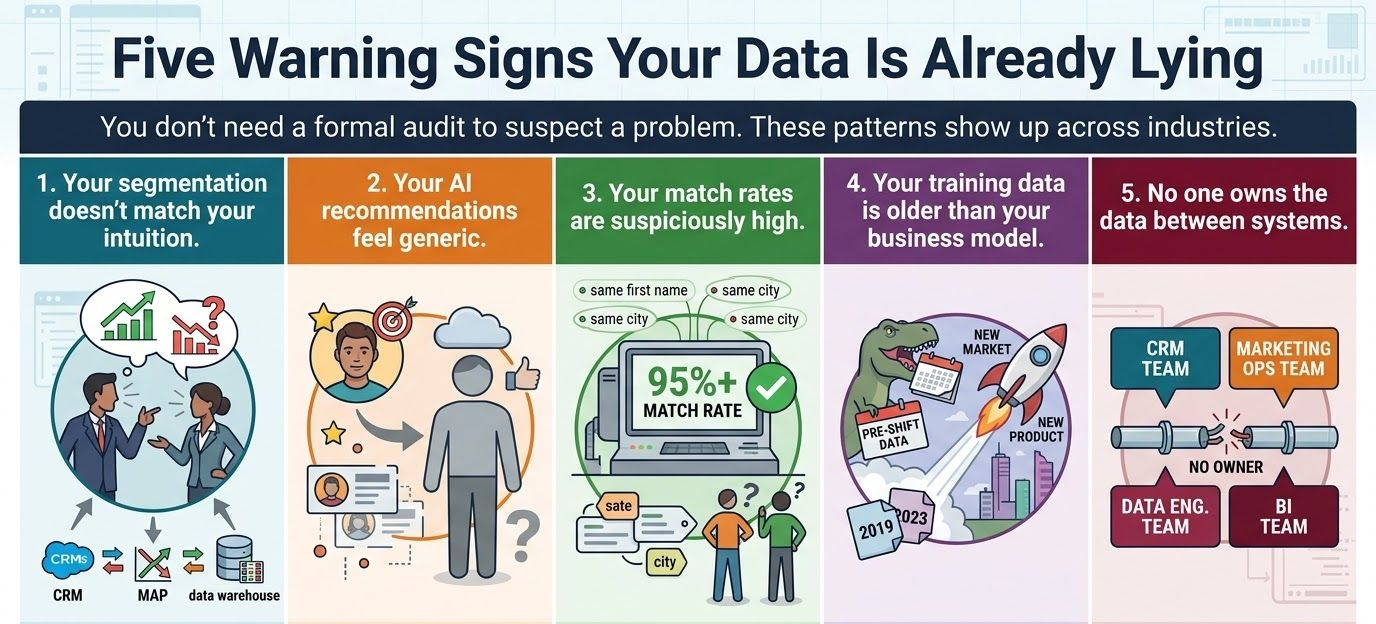
Five Warning Signs Your Data Is Already Lying
You don't need a formal audit to suspect you have a problem. These patterns show up in organizations of almost every size and industry.
Your sales team swears a particular vertical converts at a higher rate. Your model says otherwise. Before you trust the model, check whether that vertical is consistently coded across your CRM, your MAP, and your data warehouse. Inconsistent taxonomy is one of the most common — and most invisible — data quality failures in enterprise MarTech stacks.
Personalization engines that surface oddly broad recommendations are often working from sparse or contradictory customer profiles. When the underlying data is thin or inconsistent, the model defaults to the middle. It's not wrong, exactly. It's just not useful.
This one surprises people. A deduplication or identity resolution process that reports 95%+ match rates with minimal review is almost certainly over-matching — collapsing distinct records into unified profiles based on loose criteria. The confidence scores look great. The underlying data quality is a disaster waiting to surface.
AI models learn from historical patterns. If your business has shifted — new markets, new products, new customer segments, a post-merger integration — and your training data predates those shifts, you're asking a model to predict your future based on a past that no longer resembles your present.
This is the structural root of most data quality problems. Data quality degrades at handoff points. If your CRM team owns CRM data, your marketing ops team owns MAP data, and your data engineering team owns the warehouse — but no one owns the movement of data between them — you have a governance gap that compounds with every new tool you add.
The Business Case for Treating Data as Infrastructure
There's a reason organizations keep deprioritizing data quality work. It's unglamorous. It doesn't have a ribbon-cutting moment. You can't demo it to the board the way you can demo a new AI feature. And the ROI is almost always framed as cost avoidance rather than revenue generation, which makes it hard to get budget.
But here's the reframe that I think changes the conversation: data quality is not a data problem. It's an AI readiness problem.
Every dollar you spend on AI tooling, model development, and integration work is leveraged against your data. If that data is unreliable, you're not just getting worse AI outputs — you're amplifying the cost of every bad decision those outputs influence. The model becomes a multiplier for errors that already existed in your environment.
Conversely, organizations that treat data as infrastructure — that invest in quality as a continuous discipline rather than a one-time remediation project — compound the value of every AI investment they make. Clean data doesn't just produce better model outputs. It produces trustworthy outputs, which means the outputs actually get used, which means the AI investment delivers the returns it was supposed to deliver.
This distinction between AI that gets used and AI that gets abandoned is one of the most under appreciated variables in enterprise AI ROI. And it almost always traces back to data quality.
What Good Data Governance Actually Looks Like
Not the binder version. Not the three-year roadmap that gets shelved after the first reorg. The practical version that enterprises can start executing against in the next quarter.
Start with a completeness audit, not a quality audit. Before you can fix data, you need to know what you have. Field-level completeness across your critical data assets — customer records, product data, transaction history — tells you where the gaps are and where AI models will be flying blind.
Establish confidence scoring for AI outputs. Any AI system operating on enterprise data should surface, not suppress, its uncertainty. If a model is making predictions from sparse or conflicting inputs, that uncertainty should be visible to the humans acting on the output. High-confidence changes can be automated. Low-confidence changes should require human review. This isn't a failure mode — it's appropriate design.
Create a data quality SLA between systems. If data moves between your CRM, your MAP, your data warehouse, and your AI layer, each handoff should have defined quality standards. Completeness thresholds. Deduplication criteria. Field format requirements. The absence of these standards is the governance gap that kills most enterprise AI programs slowly.
Treat data quality as a product, not a project. Projects end. Products don't. Organizations that have cracked the data quality problem don't run annual remediation sprints — they build continuous monitoring, alerting, and remediation into their data operations. The goal is a living system, not a clean-room moment that degrades the second new data starts flowing.
CleanSmart: Proof of Principle, Not Just a Product
When I built CleanSmart, I wasn't solving a theoretical problem. I was solving the exact problem described above — the gap between what enterprise data looks like and what AI systems need it to look like to produce reliable outputs.
The core mechanics reflect how data quality work actually operates in production environments. SmartMatch handles deduplication using AI-based matching that distinguishes genuine duplicates from distinct-but-similar records. SmartFill predicts and completes missing field values based on contextual signals. LogicGuard flags anomalies that indicate upstream process failures rather than just bad entries. And Clarity Score gives every record a composite quality signal so you can see, at a glance, whether the data feeding your downstream systems meets the threshold your AI requires.
The human-in-the-loop workflow isn't a design compromise — it's the point. High-confidence changes process automatically. Low-confidence changes surface for review. That distinction is what separates a data quality tool from a data corruption tool running faster.
The architecture didn't come from a product roadmap. It came from watching what happens when organizations deploy AI against data they haven't interrogated. CleanSmart is the intervention that should have existed before the model was trained.
Explore CleanSmart at cleansmartlabs.com/products
The Question Worth Asking Before Your Next AI Initiative
Not "which model should we use?" Not "which vendor should we partner with?" Not even "what's our AI strategy?"
The question is simpler, and harder: Can we trust the data this AI will learn from?
If you can't answer that with confidence — if your answer involves qualifications about "known issues" or "ongoing governance work" or "it depends on which system" — then you have a sequencing problem. The AI investment is premature. Not forever. Just until the foundation is solid.
This isn't a pessimistic take on enterprise AI. It's the opposite. Organizations that get the sequencing right — data first, intelligence second — compound their AI investments in ways that organizations chasing model sophistication on dirty data never will. The gap between them isn't capability. It's discipline.
Your data is probably lying to you right now. The AI you're about to deploy will believe every word.
The question is what you're going to do about it before the model runs.
Frequently Asked Questions
How do I know if my data quality is bad enough to affect AI performance?
The most reliable early signal is disagreement between model outputs and domain expertise. When your team's intuition — built from years of direct customer interaction — consistently conflicts with what the model surfaces, that's rarely a model problem. Start by auditing completeness and deduplication rates in the data assets your models train on. If you find field-level completeness below 70% on attributes the model treats as predictive, you have a problem worth addressing before further model investment.
What's the difference between data cleaning and data governance?
Data cleaning is a point-in-time intervention — you fix what's broken today. Data governance is the system that determines whether the same problems come back tomorrow. Most organizations have done some version of data cleaning. Far fewer have built the governance infrastructure to prevent recurrence. For AI programs specifically, governance matters more than cleaning, because AI systems ingest data continuously. A one-time clean doesn't stay clean.
Can AI tools help with data quality, or is it still mostly a manual process?
AI-assisted data quality is now genuinely viable at production scale — the capability gap that made this mostly manual five years ago has closed considerably. The critical design requirement is confidence-aware automation: the system needs to distinguish high-confidence corrections it can apply automatically from lower-confidence flags that require human review. Tools that collapse this distinction and automate everything introduce a different category of data quality risk. The goal is augmentation, not replacement.


